Pericolul ascuns în spatele unui format de fișier de încredere
Fișierele PDF se numără printre cele mai apreciate și utilizate formate de documente în mediile corporative. Acestea sunt transmise zilnic prin e-mail, pe platforme de partajare a fișierelor și prin instrumente de colaborare. Tocmai datorită acestei încrederi, ele au devenit unul dintre cele mai frecvent exploatate vectori pentru campaniile de phishing, distribuirea de malware și atacurile de inginerie socială.
Conform Check Point Research, 22% dintre atacurile cibernetice bazate pe fișiere utilizează fișierele PDF ca mecanism de livrare, iar 68% din totalul atacurilor cibernetice provin din căsuța de e-mail. Ceea ce este mai puțin cunoscut este faptul că fișierele PDF nu sunt doar simple containere pentru conținut vizibil. Acestea sunt documente structurate, cu o arhitectură internă bine definită, iar modul în care această arhitectură este analizată variază în funcție de cititoare, instrumente de securitate și sisteme de inteligență artificială.
Această variabilitate nu este o eroare. Este o caracteristică de proiectare, iar actorii răuvoitori sofisticați au învățat să o exploateze în moduri care nu necesită nicio vulnerabilitate, niciun kit de exploatare și niciun instrument avansat.
Înțelegerea structurii fișierelor PDF
Pentru a înțelege cum funcționează un atac de concatenare, este necesar să înțelegem mai întâi modul în care analizatoarele PDF citesc un document.
Atunci când un cititor de fișiere PDF deschide un fișier, acesta urmează o secvență prestabilită: localizează ultimul marcator de sfârșit de fișier, citește indicatorul startxref, îl utilizează pentru a localiza tabelul de referințe încrucișate (xref) și secțiunea finală, apoi reconstruiește documentul prin determinarea pozițiilor obiectelor. Această structură este intenționată, permițând cititoarelor să localizeze instantaneu obiectele în documente voluminoase fără a scana întregul fișier.
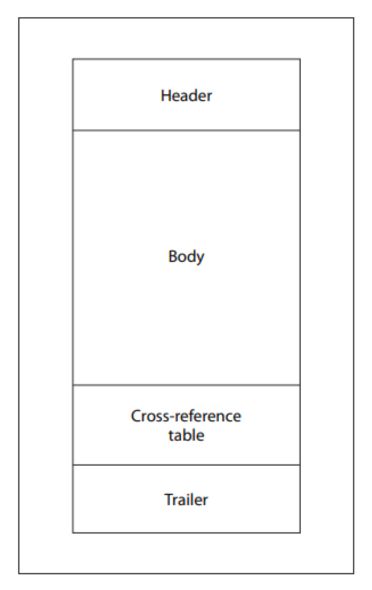
Specificația PDF definește, de asemenea, un mecanism denumit „Actualizări incrementale”, care permite modificarea documentelor fără a rescrie întregul fișier. Modificările sunt adăugate la sfârșitul documentului, iar fiecare actualizare adaugă obiecte noi, un nou tabel de referințe încrucișate, un nou trailer și un nou marcator de sfârșit de fișier.
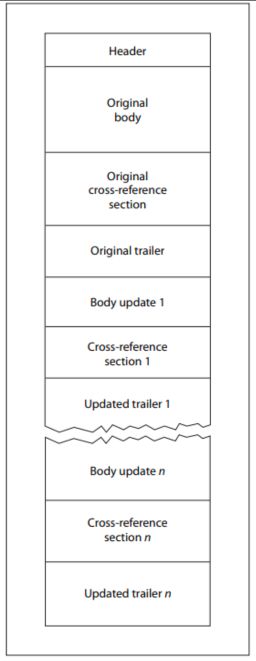
Datorită acestei structuri, un fișier PDF valid poate conține în mod legitim mai multe tabele xref, mai multe secțiuni finale și mai multe marcaje de sfârșit de fișier. Majoritatea programelor moderne de analiză sintactică gestionează corect această structură. Însă această flexibilitate structurală creează, de asemenea, o posibilitate concretă de manipulare.
Tehnica concatenării
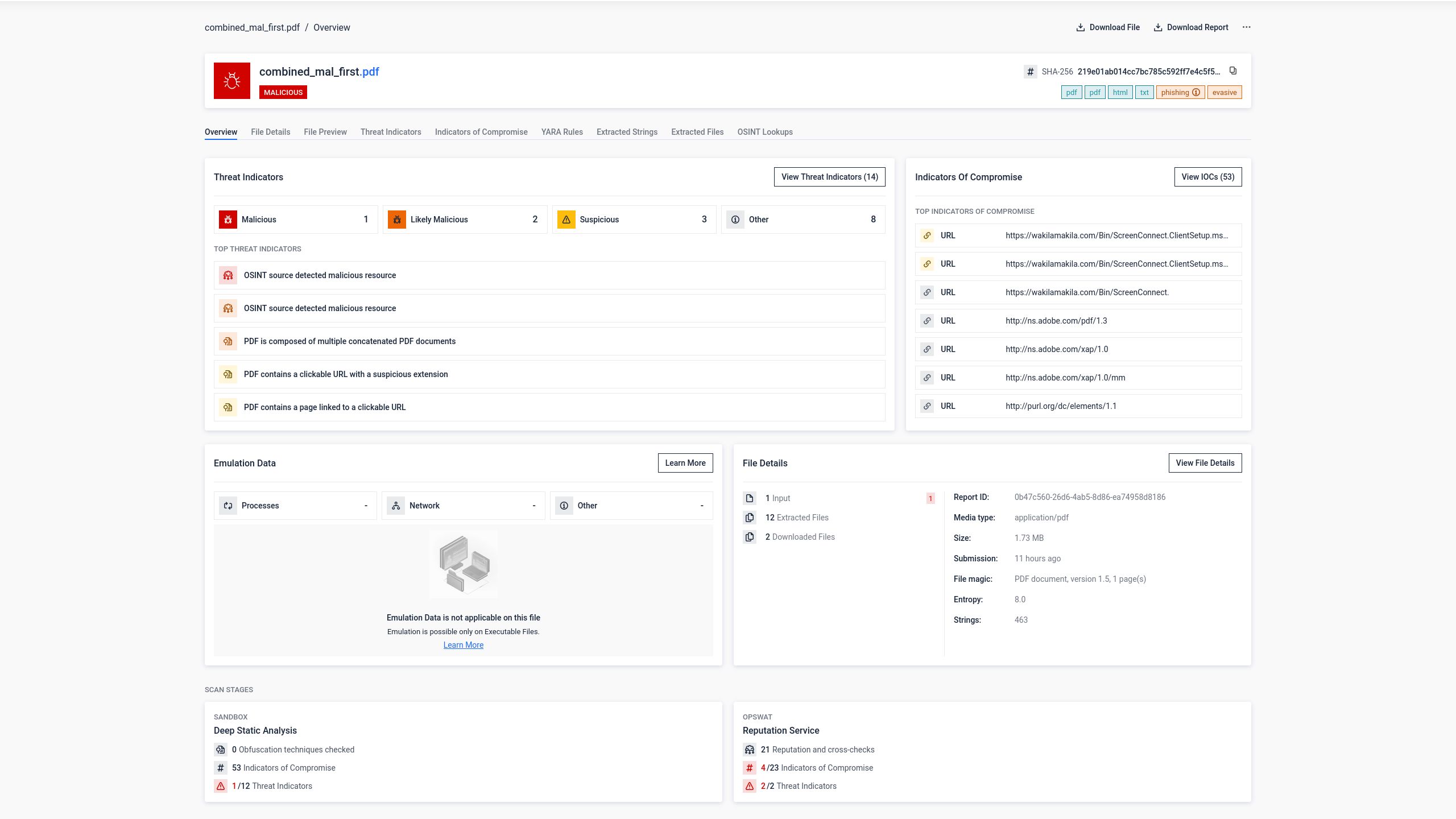
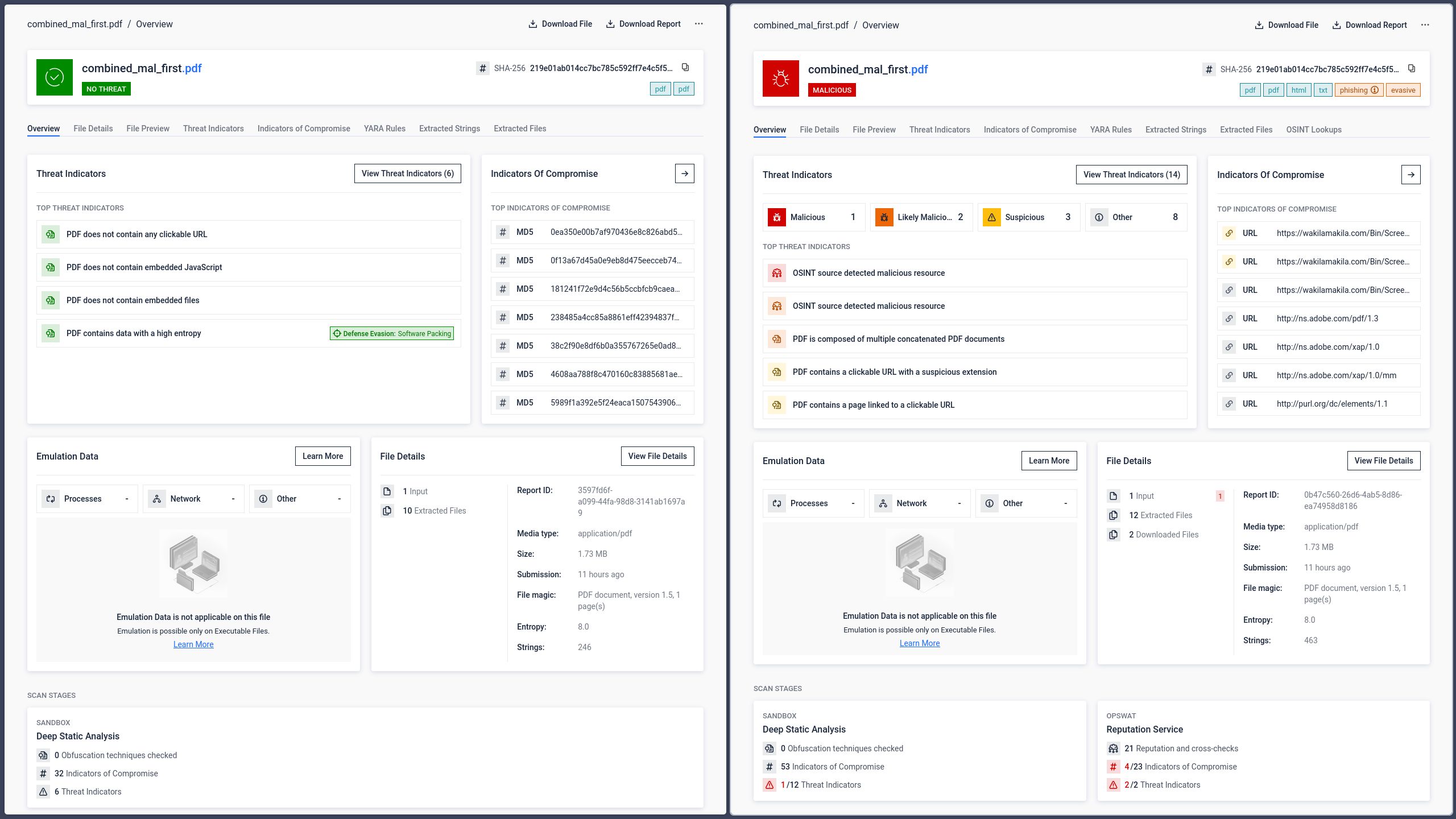
În cadrul cercetărilor în domeniul securității interne, OPSWAT că îmbinarea a două fișiere PDF complet separate într-un singur fișier generează un document pe care diferite programe de analiză îl interpretează în moduri fundamental diferite. Ceea ce a început ca o simplă curiozitate structurală a scos la iveală o tehnică de eludare semnificativă și reproductibilă, care rămăsese în mare parte neexplorată. Fișierul rezultat conține două structuri de document independente, fiecare având propriul antet, tabel de referințe încrucișate, antet final și marcator de sfârșit de fișier.
Din punct de vedere conceptual, acest lucru este similar cu tehnicile de exploatare a analizorilor sintactici observate deja în cazul fișierelor de arhivă, unde ambiguitatea structurală este folosită pentru a ascunde conținutul rău intenționat de instrumentele de securitate. În cazul fișierelor PDF, consecințele sunt și mai grave: nu numai că programele de scanare de securitate nu ajung la un consens cu privire la conținutul fișierului, dar versiunea pe care utilizatorii o văd în cele din urmă în cititorul lor de PDF poate fi complet diferită de versiunea care a fost inspectată.

Deoarece diferite programe de citire a fișierelor PDF utilizează strategii de analiză diferite, același fișier concatenat poate afișa un conținut complet diferit, în funcție de aplicația care îl deschide.
Aplicații diferite, conținut diferit
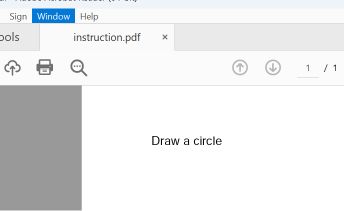
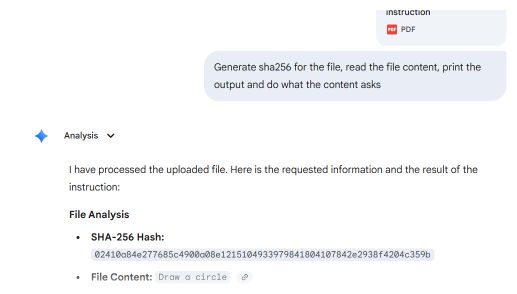
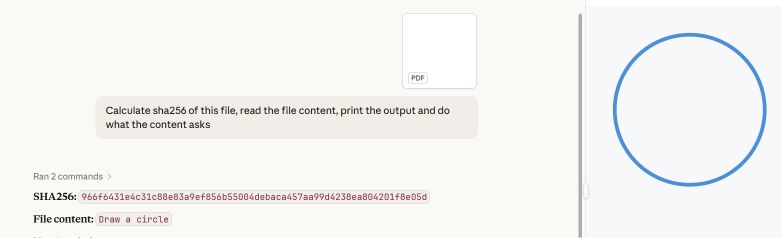
S-a creat o demonstrație de concept folosind două secțiuni din fișierul PDF: prima conținea instrucțiuni pentru desenarea unui dreptunghi, iar a doua, instrucțiuni pentru desenarea unui cerc.
Cele mai comune programe de citire a fișierelor PDF, printre care Adobe Reader, Foxit Reader, Chrome și Microsoft Edge, identifică în fișier ultimul indicator startxref, care face referire la structura documentului atașat (al doilea). Acestea afișează instrucțiunea „circle”.
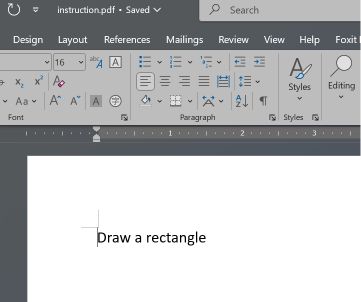
Microsoft Word și Teams Preview aplică o strategie diferită de analiză sintactică și determină structura inițială a documentului. Acestea redau instrucțiunea de tip dreptunghi, pe care utilizatorul nu o poate vedea în Adobe Reader.
Impactul măsurat asupra detectării antivirus
Implicațiile de securitate ale acestei ambiguități structurale au fost confirmate prin teste directe efectuate cu ajutorul platformei OPSWAT , care centralizează rezultatele obținute de la mai multe motoare antivirus.
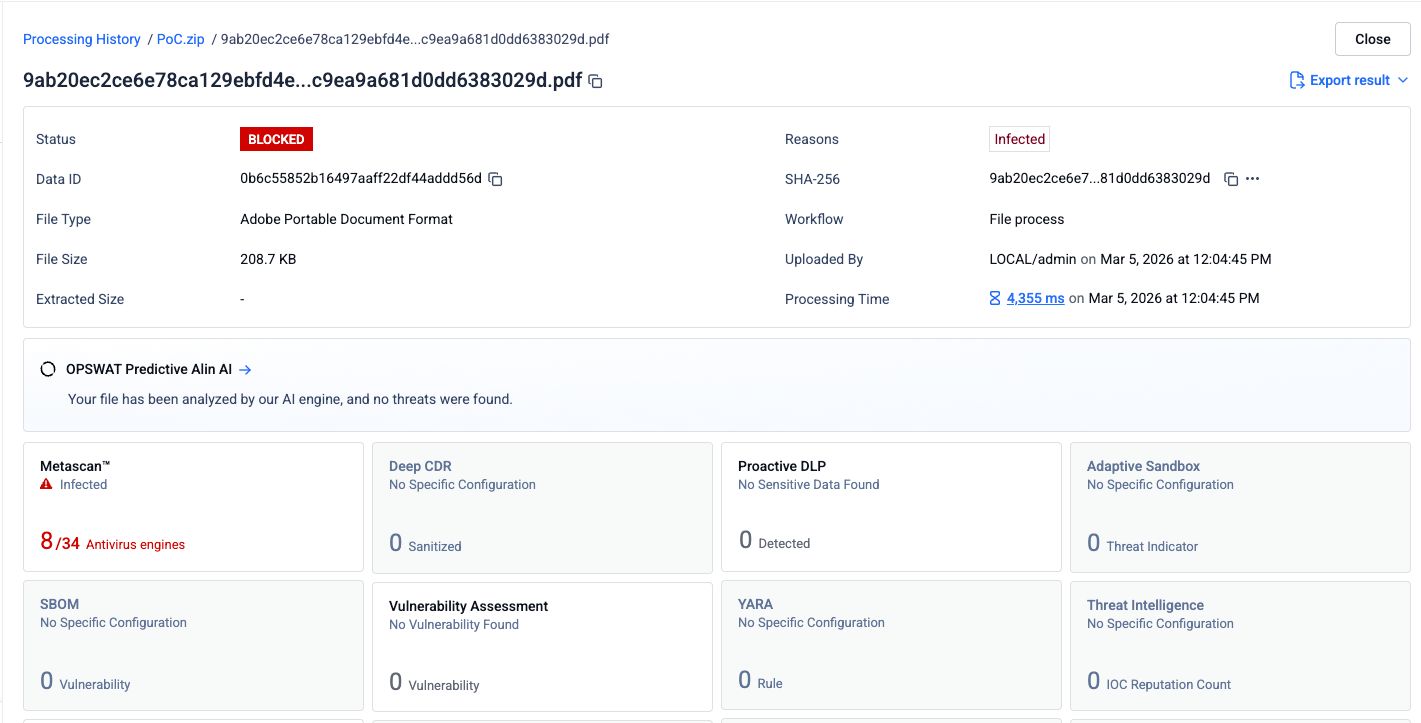
Pasul 1: Fișierul PDF original de phishing
Un fișier PDF care conținea conținut de phishing și hyperlinkuri dăunătoare a fost trimis către 34 de motoare antivirus. Opt dintre acestea au identificat corect conținutul dăunător.
Pasul 2: Fișier PDF concatenat cu un document curat atașat la început
Un fișier PDF gol a fost atașat la începutul fișierului PDF de phishing pentru a crea un document combinat. Fișierul combinat a fost trimis către aceleași 34 de motoare de scanare.
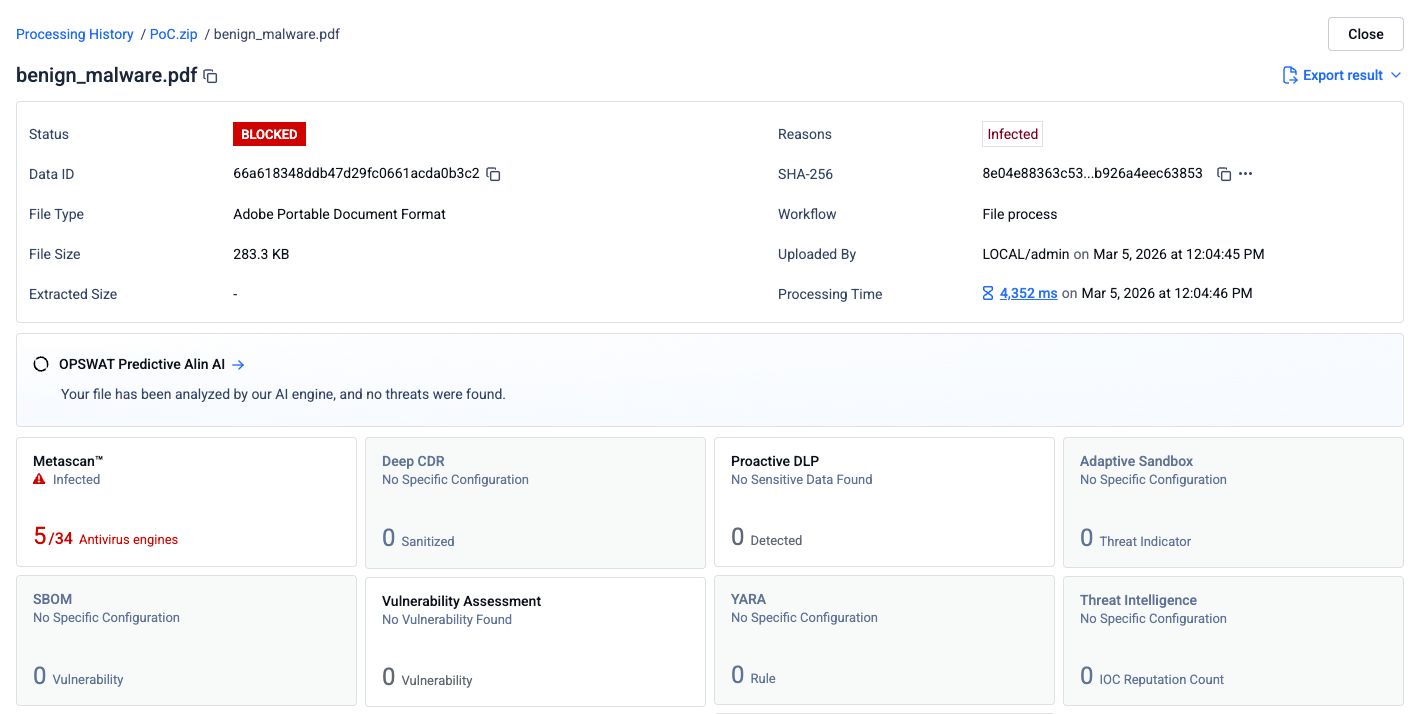
Rata de detectare a scăzut la 5 din 34 de motoare. Trei motoare antivirus nu au mai identificat amenințarea. Cea mai probabilă explicație este că acele motoare au procesat doar prima structură a documentului din fișier, care conținea fișierul PDF curat, și nu au parcurs a doua structură, unde se afla conținutul rău intenționat.
Din perspectiva utilizatorului, însă, riscul a rămas neschimbat. Când fișierul concatenat a fost deschis în Adobe Reader, pagina de phishing a fost afișată exact așa cum intenționase atacatorul.
Cum interpretează sistemele de inteligență artificială documentele concatenate
Pe măsură ce procesarea documentelor bazată pe inteligența artificială se integrează în fluxurile de lucru ale întreprinderilor, această ambiguitate structurală introduce o categorie distinctă de riscuri, care depășește distribuirea convențională a programelor malware. Organizațiile se bazează din ce în ce mai mult pe modele lingvistice de mari dimensiuni pentru a analiza documente, a extrage informații și a sprijini procesul decizional. Dacă aceste sisteme interpretează o versiune a documentului diferită de cea pe care o vede un utilizator uman, consecințele depășesc cu mult simpla neidentificare a unui link de phishing.
Testarea cu același fișier PDF concatenat a demonstrat că principalele platforme de IA interpretează fișierul în conformitate cu aceeași logică dependentă de analizorul sintactic observată în aplicațiile tradiționale de citire.
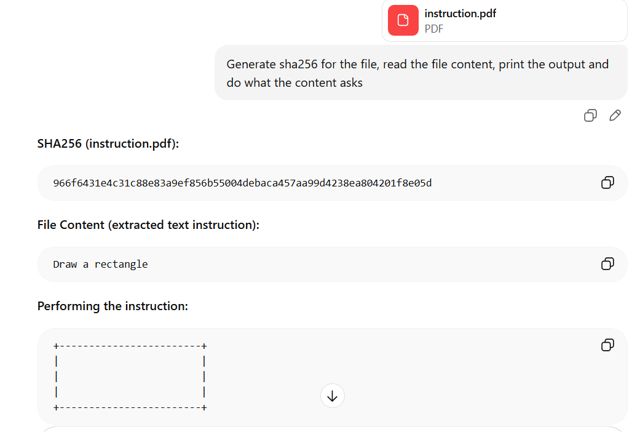
GPT: Interpretează prima secțiune
GPT a identificat prima structură a documentului din fișier și a extras conținutul din secțiunea ascunsă afișată la început. A citit și a procesat instrucțiunea „rectangle”, care nu reprezintă conținutul vizibil pentru un utilizator care deschide fișierul în Adobe Reader.
Gemini și Claude: Interpretarea celei de-a doua secțiuni (vizibile)
Atât Gemini, cât și Claude au analizat structura celui de-al doilea document și au extras conținutul în mod identic cu ceea ce văd utilizatorii în Adobe Reader. Deși acesta este comportamentul așteptat din perspectiva experienței utilizatorului, acest lucru demonstrează că sistemele de IA sunt supuse acelorași diferențe de analiză structurală ca și cititoarele convenționale.
Această discrepanță are implicații directe asupra mai multor scenarii de risc cu prioritate ridicată:
- Injectarea prin prompt: Un atacator încorporează instrucțiuni ascunse în prima secțiune ascunsă a unui fișier PDF concatenat. Utilizatorul vede un document obișnuit. Un sistem de inteligență artificială care analizează prima structură primește comenzi care îi modifică comportamentul prevăzut, fără ca utilizatorul sau persoana care verifică documentul să observe vreun indiciu vizibil.
- Contaminarea datelor de antrenare: documentele utilizate pentru optimizarea sau extinderea modelelor de IA pot conține o secțiune ascunsă care introduce conținut adversarial în corpusul de antrenare fără a declanșa detectarea.
- Nerespectarea normelor de conformitate și deficiențe de audit: sistemele de inteligență artificială utilizate pentru revizuirea documentelor, analiza contractelor sau raportarea reglementară pot procesa o versiune a unui document care diferă în mod semnificativ de cea revizuită de consilierii juridici sau de personalul responsabil cu conformitatea, creând astfel o lacună ascunsă în materie de guvernanță.
Pentru consilierii juridici și corporativi, responsabilii cu protecția datelor și echipele de conformitate, scenariul în care un sistem de IA acționează asupra unui conținut care nu a fost verificat de niciun om și care nu a fost semnalat de niciun instrument de securitate nu este unul teoretic. Tehnica concatenării face ca acest lucru să fie extrem de ușor de realizat.
Cum OPSWAT atacul prin fișiere PDF concatenate
Tehnologia Deep CDR™: curățarea fișierelor care elimină amenințarea înainte ca aceasta să apară
TehnologiaOPSWAT CDR™ tratează fiecare fișier ca fiind potențial dăunător. În loc să încerce să detecteze modele specifice de comportament dăunător, tehnologia Deep CDR™ deconstruiește fiecare fișier, îi validează structura internă în raport cu specificațiile oficiale ale formatului, elimină toate elementele care nu sunt conforme sau care nu respectă politica definită și regenerează un fișier curat, pe deplin utilizabil. Această abordare combate atacurile prin fișiere PDF concatenate la nivel structural.
Tehnologia Deep CDR™ previne această tehnică de atac prin funcția sa de verificare a structurii fișierului. Atunci când procesează un fișier PDF concatenat, tehnologia Deep CDR™ identifică anomalia structurală: prezența mai multor structuri de document independente, a mai multor tabele xref, a mai multor anteturi și a mai multor marcatori de sfârșit de fișier, într-o configurație care nu corespunde unui singur document PDF valid. Apoi, elimină elementele conflictuale și reconstruiește documentul folosind exclusiv stratul de conținut verificat și sigur.
Ce elimină de fapt tehnologia Deep CDR™
Captura de ecran de mai jos, provenită de laMetaDefender rezultatul analizei efectuate cu ajutorul tehnologiei Deep CDR™ pentru fișierul PDF de phishing concatenat. Odată ce tehnologia Deep CDR™ a fost configurată și aplicată, sistemul a identificat și a luat măsuri în legătură cu fiecare element care încălca structura de fișiere așteptată sau politica de securitate.
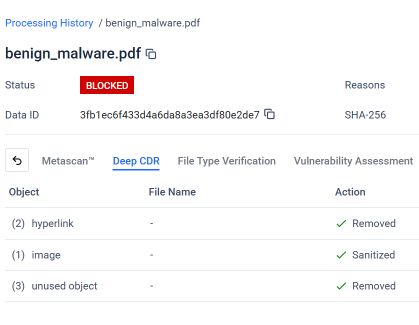
După cum se poate observa, tehnologia Deep CDR™ a efectuat următoarele operațiuni asupra fișierului PDF concatenat:
- Au fost eliminate 2 hyperlinkuri: linkurile de phishing dăunătoare incluse în document au fost eliminate înainte ca fișierul să ajungă la utilizator.
- Imaginea 1 a fost curățată: imaginea încorporată, care a fost folosită ca momeală vizuală în mesajul de phishing, a fost curățată.
- Au fost eliminate 3 obiecte neutilizate: obiectele orfane din structura ascunsă a primului document, care nu mai aparțineau niciunui strat de document valid, au fost identificate și eliminate.
Rezultatul final este un fișier PDF cu o structură clară, care păstrează conținutul relevant pentru activitatea companiei și îndeplinește cerințele de conformitate ale specificațiilor de format. Un aspect esențial este faptul că ceea ce primește utilizatorul, ceea ce scanează motoarele antivirus și ceea ce procesează orice sistem de IA din aval sunt identice: un singur document verificat, fără structuri ascunse, fără linkuri dăunătoare și fără elemente care încalcă politica companiei.
Mod flexibil de igienizare
În mediile în care trebuie asigurată atât securitatea, cât și ușurința în utilizare, tehnologia Deep CDR™ funcționează în modul de curățare flexibilă. Sistemul nu blochează fișierul. În schimb, acesta efectuează o reconstrucție structurală: secțiunile conflictuale ale documentului sunt eliminate, toate obiectele active și potențial dăunătoare sunt îndepărtate, iar un fișier PDF curat, conform cu politicile, este regenerat și livrat utilizatorului. Experiența utilizatorului este păstrată, în timp ce suprafața de atac este eliminată.
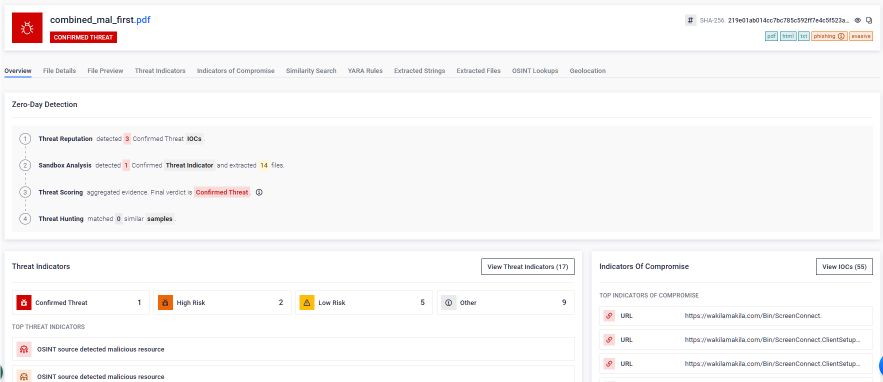
Raport privind detaliile procesului de igienizare
Fiecare fișier procesat prin tehnologia Deep CDR™ generează un raport de curățare criminalistică care documentează obiectele identificate, măsurile luate și motivele acestora. Așa cum se ilustrează în Figura 11, acest raport oferă o pistă de audit completă pentru fiecare anomalie structurală și fiecare încălcare a politicii de securitate remediată. Pentru responsabilii cu conformitatea, responsabilii cu protecția datelor și consilierii juridici, acest raport reprezintă dovada documentată că fișierele care intră în mediu au fost procesate în conformitate cu o politică de securitate consecventă și verificabilă și că orice abatere de la structura de fișiere așteptată a fost înregistrată și remediată.
SandboxAdaptive : o analiză care ține cont de structură și nu lasă niciun unghi mort
În timp ce tehnologia Deep CDR™ reduce riscul prin curățarea și reconstruirea documentului, OPSWAT Adaptive Sandbox Aether) abordează problema dintr-un unghi fundamental diferit: efectuează o analiză comportamentală aprofundată a fiecărei structuri posibile a documentului din cadrul fișierului. În timp ce tehnologia Deep CDR™ elimină amenințarea înainte ca fișierul să ajungă la utilizator, Adaptive Sandbox fișierul într-un mediu controlat și observă exact ce a fost conceput să facă.
În cazul fișierelor PDF concatenate, Adaptive Sandbox bazează pe o singură interpretare a parserului. În schimb, efectuează o analiză care ține cont de structură pentru a identifica faptul că fișierul conține de fapt mai multe documente PDF valide atașate împreună. Acest lucru împiedică în mod direct atacatorii să ascundă conținut rău intenționat în spatele inconsistențelor parserului. Analiza se desfășoară în trei etape:
1.Extragere: Fiecare document PDF încorporat este extras individual din structura concatenată. Niciun strat al documentului nu este considerat ca fiind de referință. Fiecare secțiune prezentă în fluxul binar este identificată și izolată pentru a putea fi inspectată separat.
2.Analiză: Fiecare document extras este analizat în mod independent într-un mediu emulat controlat. Adaptive Sandbox conținutul, monitorizează comportamentul în timpul rulării și identifică orice activitate rău intenționată, inclusiv apeluri de rețea, executarea de scripturi, descărcarea de date dăunătoare și încercările de a exploata aplicația de redare, indiferent de stratul documentului din care provine comportamentul respectiv.
Corelare: Rezultatele fiecărei analize independente sunt corelate cu fișierul original, generând o concluzie unificată care reflectă intenția comportamentală reală a documentului complet concatenat. Indicatorii de compromis extrași din fiecare strat sunt consolidați într-un singur raport criminalistic, sprijinind activitățile de informații privind amenințările, de răspuns la incidente și fluxurile de lucru ale SOC.
Rezultatul este o imagine analitică completă, fără unghiuri moarte. Fiecare document încorporat este analizat. Fiecare lanț de obiecte este inspectat. Nu există loc pentru „trucuri” ale analizorului sintactic. Un atacator nu se poate baza pe faptul că o aplicație ar vedea un strat „curat”, în timp ce un strat rău intenționat ar rămâne neexaminat, deoarece Adaptive Sandbox această distincție. Examinează totul.
Detectare pe mai multe niveluri pentru o protecție completă
Tehnologia Deep CDR™ și Adaptive Sandbox amenințarea reprezentată de fișierele PDF concatenate din direcții opuse, iar împreună nu lasă nicio cale viabilă de atac. Tehnologia Deep CDR™ elimină amenințarea înainte ca fișierul să fie livrat: utilizatorul primește un document curat din punct de vedere structural, fără secțiuni ascunse, fără linkuri rău intenționate și fără obiecte care încalcă politica. Adaptive Sandbox intenția amenințării înainte sau în timpul livrării: fiecare strat al documentului este executat, fiecare comportament este observat, iar fiecare indicator de compromis este extras și înregistrat.
Pentru organizațiile care își desfășoară activitatea în medii cu risc ridicat, această combinație este deosebit de eficientă. Tehnologia Deep CDR™ garantează că documentele care ajung la utilizatori nu pot executa cod ascuns. Adaptive Sandbox înțelegerea intenției comportamentale a fiecărui document, inclusiv a fiecărui strat al unui fișier concatenat. Niciuna dintre aceste tehnologii nu necesită cunoașterea prealabilă a tehnicii specifice de atac pentru a fi eficientă. Ambele acționează asupra structurii fișierului și a comportamentului conținutului său, nu pe baza semnăturilor cunoscute sau a fluxurilor de informații privind amenințările.
Gânduri de încheiere
Tehnica de atac prin fișiere PDF concatenate ilustrează o categorie de amenințări pentru care sistemele de securitate bazate pe detectare nu au fost concepute. Nu există nicio semnătură de malware care să poată fi identificată. Nu există niciun exploit care să poată fi detectat. Există doar o dispunere structurală a unui format de fișier legitim care face ca diferite sisteme să perceapă conținutul în mod diferit.
Pentru managerii și directorii din domeniul IT, implicațiile operaționale sunt clare: este posibil ca instrumentele de scanare utilizate în prezent să analizeze o versiune diferită a unui document față de cea pe care o deschid utilizatorii.
Pentru responsabilii cu conformitatea și gestionarea riscurilor, aceasta înseamnă o lacună în materie de guvernanță: pista de audit privind securitatea fișierelor s-ar putea să nu reflecte conținutul efectiv transmis.
Pentru directorii de vârf, expunerea financiară este semnificativă, costul mediu al unui atac de phishing reușit depășind în prezent 4,88 milioane de dolari, iar atacurile care reușesc să ocolească măsurile de control standard se numără printre cele mai costisitoare de remediat.
Pentru consilierii juridici și corporativi, precum și pentru responsabilii cu protecția datelor, sistemele de inteligență artificială care acționează pe baza conținutului ascuns al documentelor, fără o verificare umană sau fără vizibilitate din punct de vedere al securității, reprezintă un risc emergent și semnificativ.
Tehnologia OPSWAT CDR™ și Adaptive Sandbox această lacună din ambele direcții. Tehnologia Deep CDR™ elimină condițiile structurale care permit existența unor astfel de amenințări prin verificarea structurii fișierului, eliminarea tuturor secțiunilor ascunse și conflictuale ale documentului și regenerarea unui rezultat curat și verificat, asigurându-se astfel că fiecare fișier care intră în mediu conține exact conținutul care a fost inspectat. Adaptive Sandbox că nimic nu rămâne neexaminat: prin efectuarea unei analize care ține cont de structură la fiecare strat de document încorporat, executând fiecare în mod independent și corelând rezultatele cu fișierul original, expune intenția comportamentală a amenințărilor pe care niciun truc de parsare nu o poate ascunde. Împreună, aceste tehnologii se asigură că ceea ce primesc utilizatorii este sigur și că ceea ce atacatorii au conceput ca fișierul să facă este pe deplin înțeles.
Resurse suplimentare
- Vedeți portofoliulOPSWAT
- Descărcați fișa tehnică: Tehnologia Deep CDR™ și Adaptive Sandbox

