Falsificarea fișierelor rămâne una dintre cele mai eficiente tehnici folosite de atacatori pentru a ocoli controalele de securitate tradiționale. Anul trecut, OPSWAT a introdus un motor de detectare a tipurilor de fișiere îmbunătățit cu inteligență artificială pentru a acoperi lacunele lăsate de instrumentele tradiționale. Anul acesta, cu Modelul de detectare a tipurilor de fișiere v3, am avansat această capacitate, concentrându-ne asupra tipurilor de fișiere pentru care acuratețea contează cel mai mult și pentru care sistemele tradiționale bazate pe logică eșuează în mod constant.
Modelul de detectare a tipurilor de fișiere OPSWAT v3 este conceput pentru a răspunde unei provocări specifice de clasificare fiabilă a fișierelor ambigue și nestructurate, în special a formatelor bazate pe text, cum ar fi scripturile, fișierele de configurare și codul sursă. Spre deosebire de clasificatorii generalizați, acest model a fost creat special pentru cazurile de utilizare în domeniul securității cibernetice, în care clasificarea eronată a unui script shell sau eșecul de a detecta un document care conține macro-uri încorporate, cum ar fi un fișier Word cu cod VBA, poate introduce un risc de securitate semnificativ.
De ce este esențială detectarea corectă a tipului de fișier
Majoritatea sistemelor de detectare se bazează pe trei abordări comune:
- Extensia fișierului: Această metodă verifică numele fișierului pentru a-i determina tipul pe baza extensiei, cum ar fi .doc sau .exe. Este rapidă și larg compatibilă pe toate platformele. Cu toate acestea, este ușor de manipulat. Un fișier rău intenționat poate fi redenumit cu o extensie care pare sigură, iar unele sisteme ignoră complet extensiile, ceea ce face ca această abordare să nu fie fiabilă.
- Bytes magici: Acestea sunt secvențe fixe găsite la începutul multor fișiere structurate, cum ar fi PDF-urile sau imaginile. Această metodă îmbunătățește precizia față de extensiile de fișier prin examinarea conținutului real al fișierului. Dezavantajul este că nu toate tipurile de fișiere au modele de octeți bine definite. Octeții magici pot fi, de asemenea, falsificați, iar standardele inconsecvente între instrumente pot duce la confuzie.
- Analiza distribuției caracterelor: Această metodă analizează conținutul real al unui fișier pentru a deduce tipul acestuia. Este deosebit de utilă pentru identificarea formatelor bazate pe text slab structurate, cum ar fi scripturile sau fișierele de configurare. Deși oferă o perspectivă mai profundă, are costuri de procesare mai ridicate și poate produce rezultate fals pozitive cu conținut neobișnuit. De asemenea, este mai puțin eficientă pentru fișierele binare care nu au modele de caractere lizibile.
Aceste metode funcționează bine pentru formatele structurate, dar devin nesigure atunci când sunt aplicate fișierelor nestructurate sau bazate pe text. De exemplu, un script shell cu comenzi minime poate semăna foarte mult cu un fișier text simplu. Multe dintre aceste fișiere nu au antete puternice sau marcaje coerente, ceea ce face ca clasificarea bazată pe modele de octeți sau extensii să fie insuficientă. Atacatorii exploatează această ambiguitate pentru a deghiza scripturi malițioase în documente sau jurnale inofensive.
Instrumentele vechi precum TrID și LibMagic nu au fost concepute pentru acest nivel de nuanță. Deși eficiente pentru categorizarea generală a fișierelor, acestea au fost optimizate pentru amploare și viteză, nu pentru detectarea specializată în cadrul constrângerilor de securitate.
Cum funcționează modelul de detectare a tipului de fișier v3
Procesul de formare a modelului de detectare a tipurilor de fișiere v3 constă în două etape. În prima etapă, se efectuează o preinstruire adaptată domeniului utilizând Masked Language Modeling (MLM), permițând modelului să învețe sintaxa și tiparele structurale specifice domeniului. În a doua etapă, modelul este ajustat pe un set de date supravegheat în care fiecare fișier este adnotat în mod explicit cu tipul său real de fișier.
Setul de date este un amestec de fișiere obișnuite și eșantioane de amenințări, asigurând un echilibru puternic între acuratețea din lumea reală și relevanța pentru securitate. OPSWAT menține controlul asupra datelor de instruire, permițând perfecționarea continuă a formatelor care contează cel mai mult pentru operațiunile de securitate.
Componenta AI este aplicată cu precizie, nu la scară largă. File Type Detection Model v3 se concentrează asupra tipurilor de fișiere ambigue și nestructurate pe care metodele tradiționale de detectare nu le pot gestiona eficient, cum ar fi scripturile, jurnalele și textul slab formatat în care structura este inconsistentă sau absentă. Timpul mediu de inferență rămâne sub 50 de milisecunde, ceea ce îl face eficient pentru fluxurile de lucru în timp real în ceea ce privește încărcarea securizată a fișierelor, punerea în aplicare a endpoint-urilor și conductele de automatizare.
Rezultate de referință
Am comparat motorul de detectare a tipurilor de fișiere OPSWAT cu principalele instrumente de detectare a tipurilor de fișiere utilizând un set de date mare și divers. Comparația a inclus scoruri F1 pentru 248.000 de fișiere și aproximativ 100 de tipuri de fișiere.
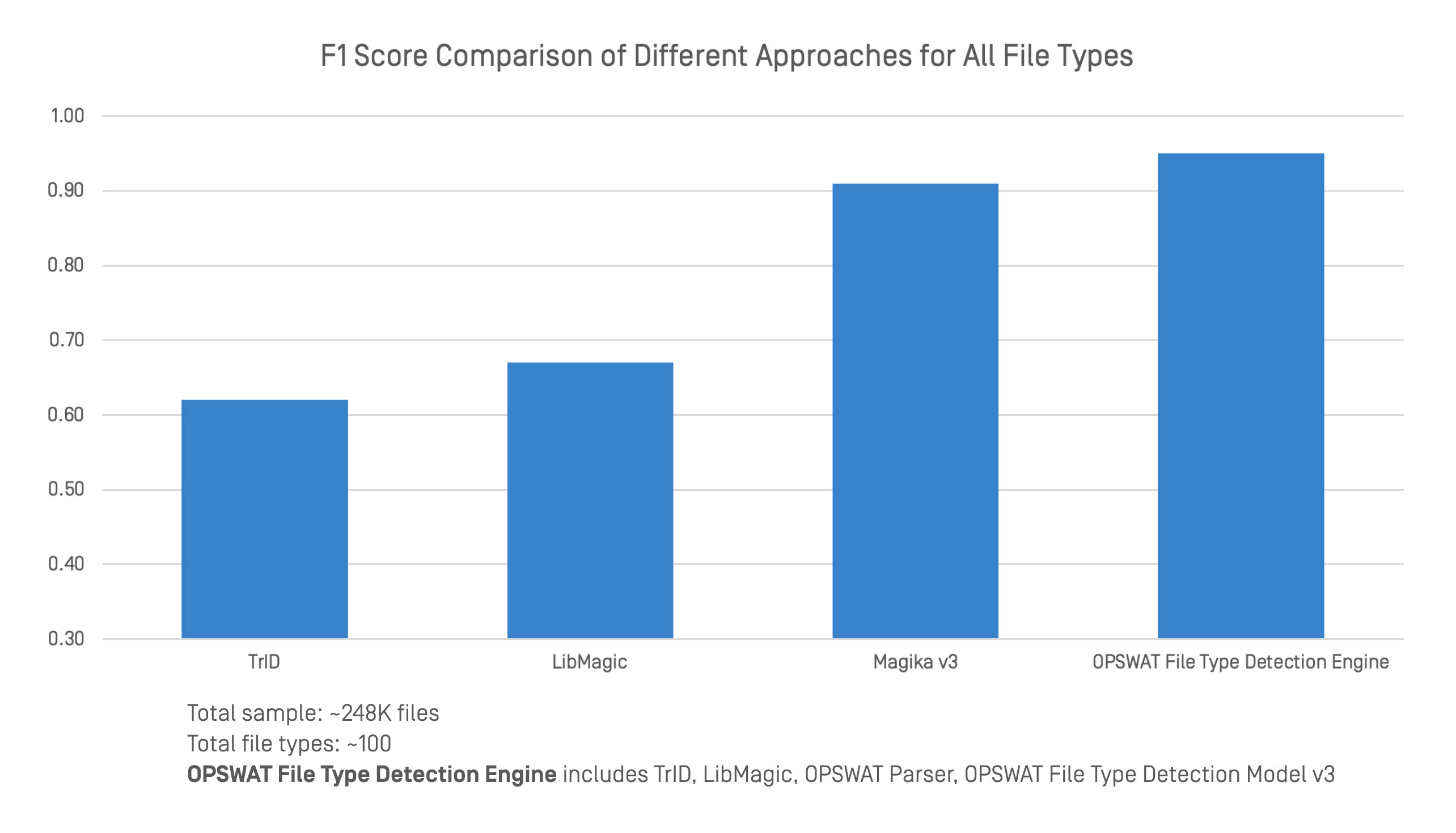
Motorul de detectare a tipurilor de fișiere OPSWAT integrează mai multe tehnici, inclusiv TrID, LibMagic și tehnologiile proprii ale OPSWAT, cum ar fi analizoarele avansate și modelul de detectare a tipurilor de fișiere v3. Această abordare combinată oferă o clasificare mai puternică și mai fiabilă atât în formate structurate, cât și nestructurate.
În cadrul testelor de referință, motorul a obținut o acuratețe generală mai mare decât orice alt instrument izolat. În timp ce TrID, LibMagic și Magika v3 au performanțe bune în anumite domenii, precizia lor scade atunci când lipsesc antetele fișierelor sau conținutul este ambiguu. Prin stratificarea detecției tradiționale cu analiza profundă a conținutului, OPSWAT menține o performanță constantă chiar și atunci când structura este slabă sau intenționat înșelătoare.
Fișiere text și script
Formatele bazate pe text și scripturi sunt adesea implicate în amenințările transmise prin fișiere și în deplasările laterale. Am efectuat un test concentrat pe 169.000 de fișiere în formate precum .sh, .py, .ps1, și .conf.
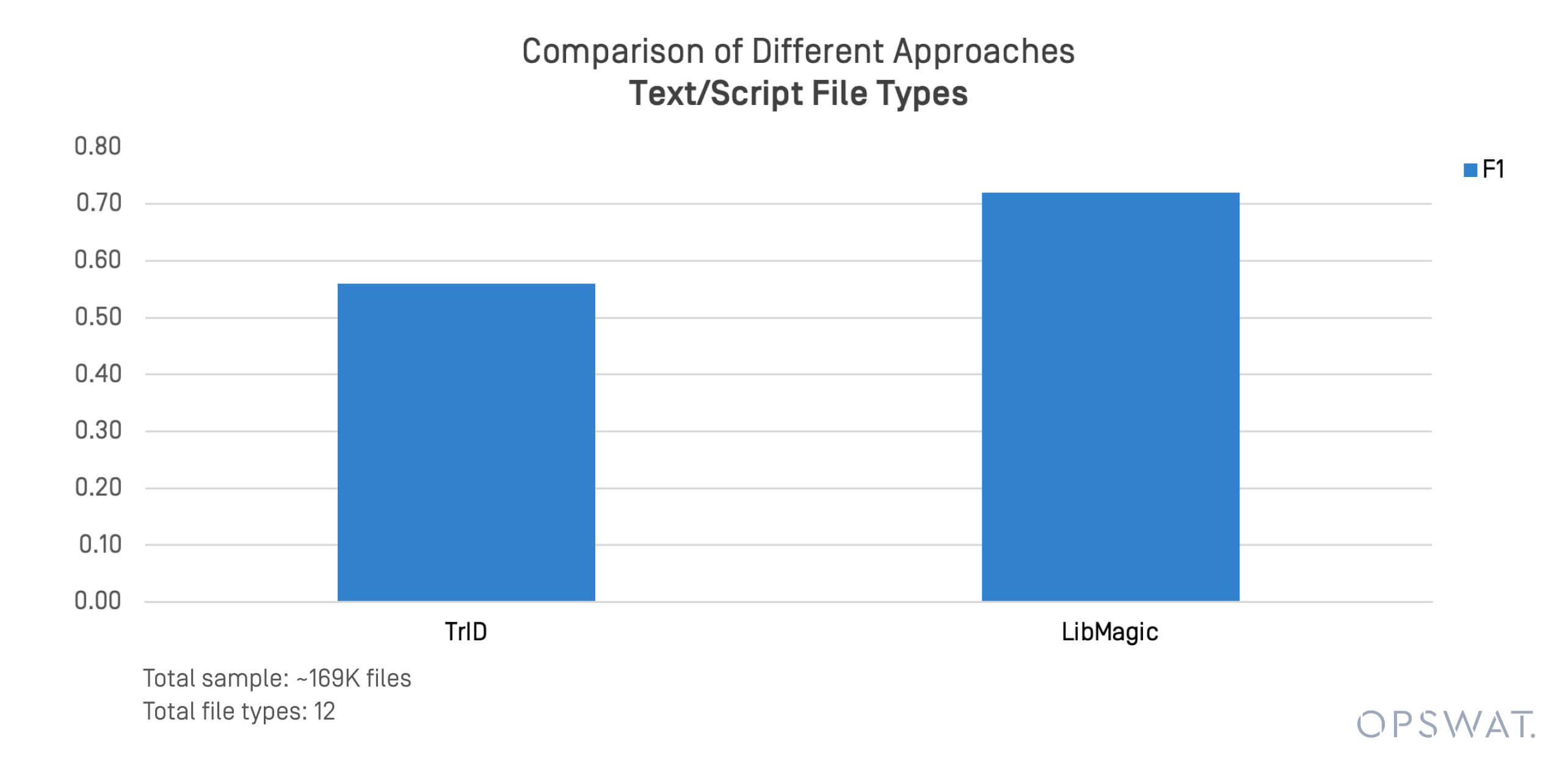
TrID și LibMagic au arătat limitări în detectarea acestor fișiere nestructurate. Performanța lor s-a degradat rapid atunci când conținutul fișierului a deviat de la tiparele de octeți așteptate.
Model de detectare a tipului de fișier v3 vs Magika v3
Am evaluat OPSWAT File Type Detection Model v3 față de Magika v3, clasificatorul AI open-source al Google, pentru 30 de tipuri de fișiere text și script, utilizând același set de date de 500.000 de fișiere.
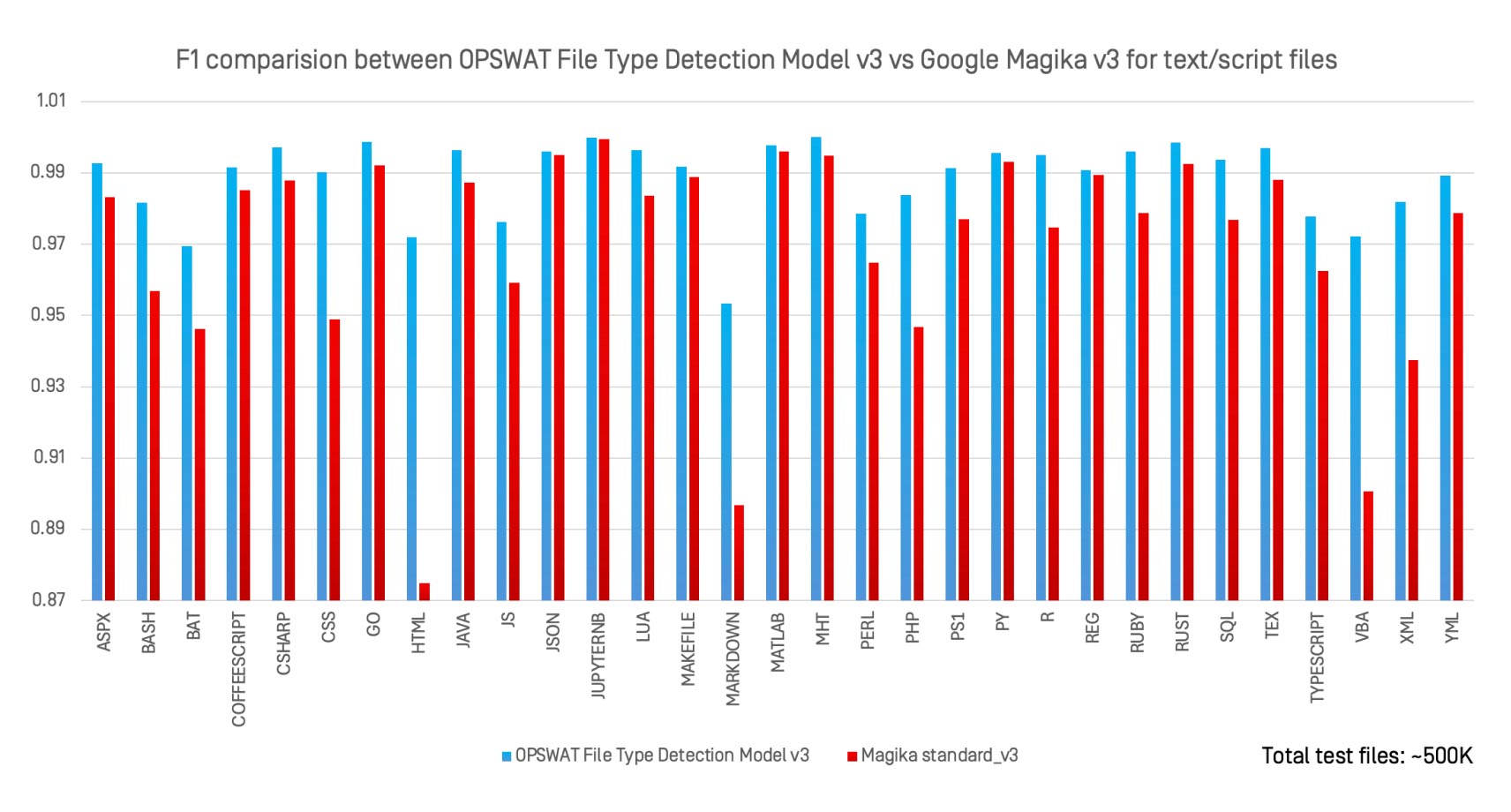
Observații cheie:
- File Type Detection Model v3 a egalat sau a depășit Magika în aproape toate formatele.
- Cele mai mari creșteri au fost observate în formate vag definite, cum ar fi
.bat, .perl, .html,și .xml. - Spre deosebire de Magika, care este proiectat pentru identificarea de uz general, File Type Detection Model v3 este optimizat pentru formatele cu risc ridicat unde clasificarea greșită are implicații serioase asupra securității.
Principalele cazuri de utilizare
Încărcări, descărcări și transferuri de fișiere Secure
Preveniți pătrunderea în mediul dvs. a fișierelor deghizate sau malițioase prin intermediul portalurilor web, al atașamentelor de e-mail sau al sistemelor de transfer de fișiere. Detecția îmbunătățită de inteligență artificială merge dincolo de extensii și antete MIME pentru a identifica scripturi, macro-uri sau executabile încorporate în fișierele redenumite.
Conducte DevSecOps
Opriți artefactele nesigure înainte ca acestea să vă contamineze mediile de creare sau implementare a software-ului. Prin validarea adevăratului tip de fișier pe baza conținutului real, MetaDefender Core se asigură că numai formatele aprobate trec prin conductele CI/CD, reducând riscul atacurilor din lanțul de aprovizionare și menținând conformitatea cu practicile de dezvoltare sigură.
Aplicarea normelor de conformitate
Detectarea exactă a tipurilor de fișiere este esențială pentru îndeplinirea mandatelor de reglementare precum HIPAA, PCI DSS, GDPR și NIST 800-53, care necesită un control strict asupra integrității datelor și securității sistemului. Detectarea și blocarea tipurilor de fișiere falsificate sau neautorizate ajută la aplicarea politicilor care previn expunerea datelor sensibile, mențin pregătirea pentru audit și evită sancțiuni costisitoare.
Gânduri finale
Clasificatoarele de fișiere cu scop general, precum Magika, sunt utile pentru categorizarea conținutului general. Dar în securitatea cibernetică, precizia contează mai mult decât acoperirea. Un singur script clasificat greșit sau o singură macro-etichetă greșită pot face diferența între izolare și compromitere.
Motorul OPSWAT File Type Detection oferă această precizie. Prin combinarea analizei tipului de fișier îmbunătățită prin inteligență artificială cu metode de detecție dovedite, acesta oferă un nivel fiabil de clasificare acolo unde instrumentele tradiționale eșuează, în special în formate ambigue sau nestructurate. Nu este vorba despre a înlocui totul; este vorba despre consolidarea punctelor slabe critice din stiva dvs. de securitate cu detecție în timp real, în funcție de context.

